

In the world of data science, the quality and integrity of data play a critical role in driving accurate and meaningful insights. Data often comes in various forms, with different scales and distributions, making it challenging to compare and analyze across different variables. This is where standardization comes into the picture. In this blog, we will explore the significance of standardization in data science, specifically focusing on voluntary carbon markets and carbon offsetting as examples. We will also provide code examples using a dummy dataset to showcase the impact of standardization techniques on data.
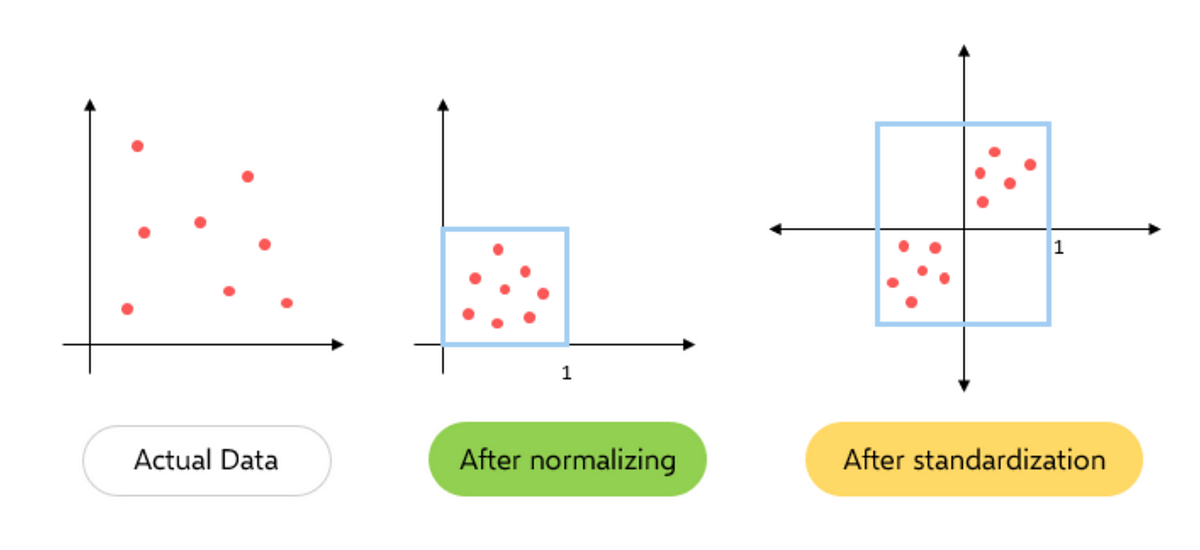
Standardization, also known as feature scaling, transforms variables in a dataset to a common scale, enabling fair comparison and analysis. It ensures that all variables have a similar range and distribution, which is crucial for various machine learning algorithms that assume equal importance among features.
Standardization is important for several reasons:
- It makes features comparable: When features are on different scales, it can be difficult to compare them. Standardization ensures that all features are on the same scale, which makes it easier to compare them and interpret the results of machine learning algorithms.
- It improves the performance of machine learning algorithms: Machine learning algorithms often work best when the features are on a similar scale. Standardization can help to improve the performance of these algorithms by ensuring that the features are on a similar scale.
- It reduces the impact of outliers: Outliers are data points that are significantly different from the rest of the data. Outliers can skew the results of machine learning algorithms. Standardization can help to reduce the impact of outliers by transforming them so that they are closer to the rest of the data.
Standardization should be used when:
- The features are on different scales.
- The machine learning algorithm is sensitive to the scale of the features.
- There are outliers in the data.

Z-score Standardization (StandardScaler)
This technique transforms data to have zero(0) mean and unit(1) variance. It subtracts the mean from each data point and divides it by the standard deviation.
The formula for Z-score standardization is:
- Z = (X — mean(X)) / std(X)
Min-Max Scaling (MinMaxScaler)
This technique scales data to a specified range, typically between 0 and 1. It subtracts the minimum value and divides by the range (maximum—minimum).
The formula for Min-Max scaling is:
- X_scaled = (X — min(X)) / (max(X) — min(X))
Robust Scaling (RobustScaler)
This technique is suitable for data with outliers. It scales data based on the median and interquartile range, making it more robust to extreme values.
The formula for Robust scaling is:
- X_scaled = (X — median(X)) / IQR(X)
where IQR is the interquartile range.
To illustrate the impact of standardization techniques, let’s create a dummy dataset representing voluntary carbon markets and carbon offsetting. We’ll assume the dataset contains the following variables: ‘Retirements’, ‘Price’, and ‘Credits’.
#Import necessary libraries
import pandas as pd from sklearn.preprocessing import StandardScaler, MinMaxScaler, RobustScaler
#Create a dummy dataset
data = {'Retirements': [100, 200, 150, 250, 300],
'Price': [10, 20, 15, 25, 30],
'Credits': [5, 10, 7, 12, 15]} df = pd.DataFrame(data)
#Display the original dataset
print("Original Dataset:")
print(df.head())

#Perform Z-score Standardization
scaler = StandardScaler()
df_standardized = pd.DataFrame(scaler.fit_transform(df), columns=df.columns)#Display the standardized dataset
print("Standardized Dataset (Z-score Standardization)")
print(df_standardized.head())

#Perform Min-Max Scaling
scaler = MinMaxScaler()
df_scaled = pd.DataFrame(scaler.fit_transform(df), columns=df.columns)#Display the scaled dataset
print("Scaled Dataset (Min-Max Scaling)")
print(df_scaled.head())

# Perform Robust Scaling
scaler = RobustScaler()
df_robust = pd.DataFrame(scaler.fit_transform(df), columns=df.columns)# Display the robustly scaled dataset
print("Robustly Scaled Dataset (Robust Scaling)")
print(df_robust.head())

Standardization is a crucial step in data science that ensures fair comparison, enhances algorithm performance, and improves interpretability. Through techniques like Z-score Standardization, Min-Max Scaling, and Robust Scaling, we can transform variables into a standard scale, enabling reliable analysis and modelling. By applying appropriate standardization techniques, data scientists can unlock the power of data and extract meaningful insights in a more accurate and efficient manner.
By standardizing the dummy dataset representing voluntary carbon markets and carbon offsetting, we can observe the transformation and its impact on the variables ‘Retirements’, ‘Price’, and ‘Credits’. This process empowers data scientists to make informed decisions and create robust models that drive sustainability initiatives and combat climate change effectively.
Remember, standardization is just one aspect of data preprocessing, but its importance cannot be underestimated. It sets the foundation for reliable and accurate analysis, enabling data scientists to derive valuable insights and contribute to meaningful advancements in various domains.
Happy standardizing!
{kind=link}