
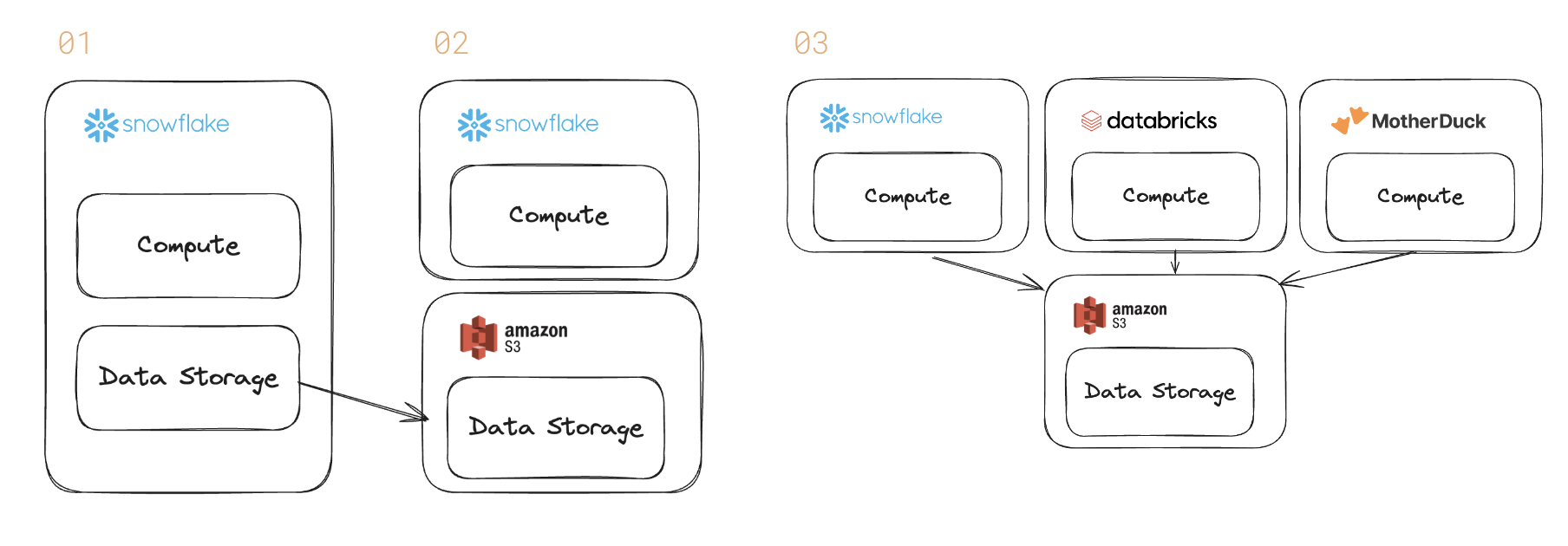
The database is being unbundled. Historically, a database like Snowflake sold both data storage & a query engine (& the computing power to execute the query). That’s step 1 above.
But, customers are pushing for a deeper separation of compute & storage. The recent Snowflake earnings call highlighted the trend. Larger customers prefer open formats for interoperability (step 2 & 3).
A lot of big customers want to have open file formats to give them the options…So data interoperability is very much a thing and our AI products can generally act on data that is sitting in cloud storage as well.
We do expect a number of our large customers are going to adopt Iceberg formats and move their data out of Snowflake where we lose that storage revenue and also the compute revenue associated with moving that data into Snowflake.
Instead of locking the data in one database, customers prefer to have it in open formats like Apache Arrow, Apache Parquet, Apache Iceberg.
As data use inside of an enterprise has expanded, so has the diversity of demands on that data.
Rather than copying it each time for a different purpose whether it’s exploratory analytics, business intelligence, or AI workloads, why not centralize the data and then have many different systems access it?
This saves money : Storage is about $280m-300m overall for Snowflake.
As a reminder, about 10% to 11% of our overall revenue is associated with storage.
But it also simplifies architectures.
It also ushers in an epoch where the query engines will compete for different workloads with price & performance. Snowflake may be better for large-scale BI ; Databricks’ Spark for AI data pipelines ; MotherDuck for interactive analytics.
Data warehouse vendors have marketed the separation of storage & compute in the past. But, that message was about scaling the system to handle bigger data within their own product.
Customers demand a deeper separation – a world in which databases don’t charge for storage.
{kind=link}