
If you were to watch three videos on YouTube Shorts – one on Italian cooking, one on chess openings, & a third on crypto trading, YouTube Shorts’ recommendation algorithm combines the video descriptions with your dwell time.
Watching the osso bucco video to its end would trigger more Italian cooking specialty videos in your feed.
We believe every LLM-based application will need this capability.
Combining text & structured data in an LLM workflow the right way is difficult. It requires a new software infrastructure layer: a vector computer.
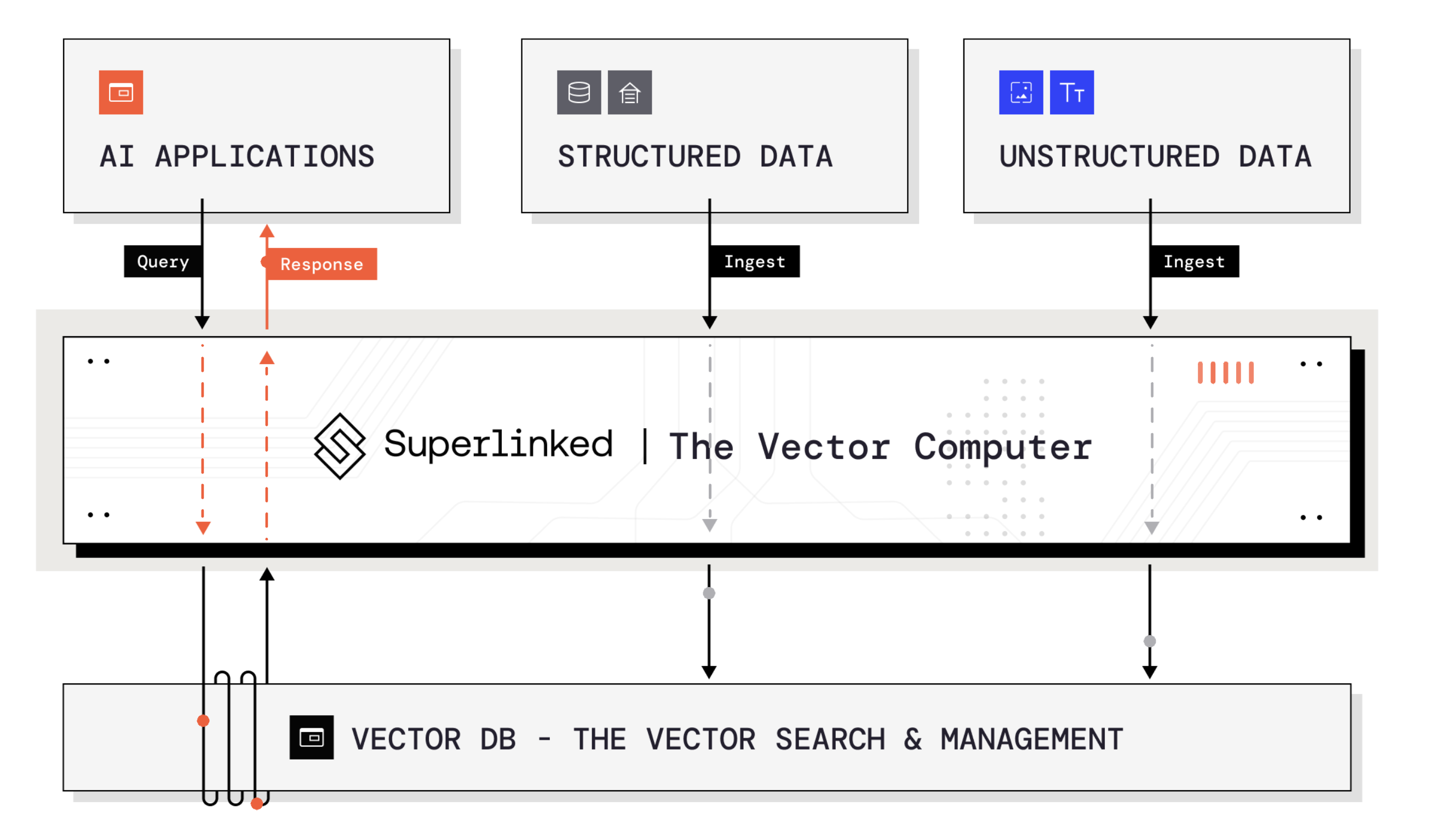
Vector computers simplify many kinds of data into vectors – the language of AI systems – and push them into your vector database.
As Spark has become the system for transforming large volumes of data in BI & AI training, the vector computer manages the data pipelines to feed models, optimizing them for a purpose or user.
Today, most vectors are very simple, but increasingly, vectors will have all kinds of data embedded in them, & vector computers will be the engines that unleash those powerful combinations.
Superlinked is building a vector computer. Founder Daniel Svonava is a former engineer at YouTube who worked on real-time machine learning systems for a decade.
Vector computers improve LLM accuracy by helping to surface the right data for Retrieval Augmented Generation (RAG). They allow faster optimization of LLMs by including many kinds of data that can be updated quickly.
Other techniques for LLM optimization require retraining or fine-tuning. These work, but take time. Standard LLM stacks of the (not-so-distant) future will leverage both RAG & fine-tuning.
Superlinked is now in product preview, working with several major infrastructure partners like MongoDB, Redis, Dataiku, & others. If you’d like to learn more, click here.
We’re thrilled to be partnering with Daniel & Ben.
{kind=link}