
Open source models have become a critical part of the AI landscape.
I was curious about the trends in the open source ecosystem, so I analyzed HuggingFace data on the top 300 open source models, both by overall usage & also the top of the trending list.
Open source models are governed by open source licenses. Similar to regular open source software, Apache & MIT dominate the licenses by model count. 76% of the top models choose one of these licenses. Apache is nearly twice as popular as MIT.

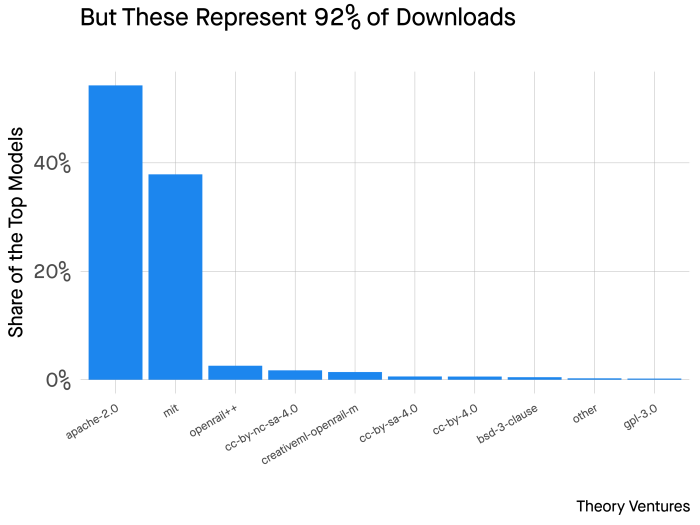
But the concentration is greater when viewing the share by downloads. Models with Apache or MIT licenses represent 92% of downloaded models last month.
Stability, Facebook, & Microsoft top the creator list of open source models by count. So does TheBloke, an engineer who quantizes (or compresses) open source models.

But the download data shows very different patterns.

Meta’s models recorded 30% of downloads, driven by its word2vec model for speech recognition. Then OpenAI & Google not far behind.
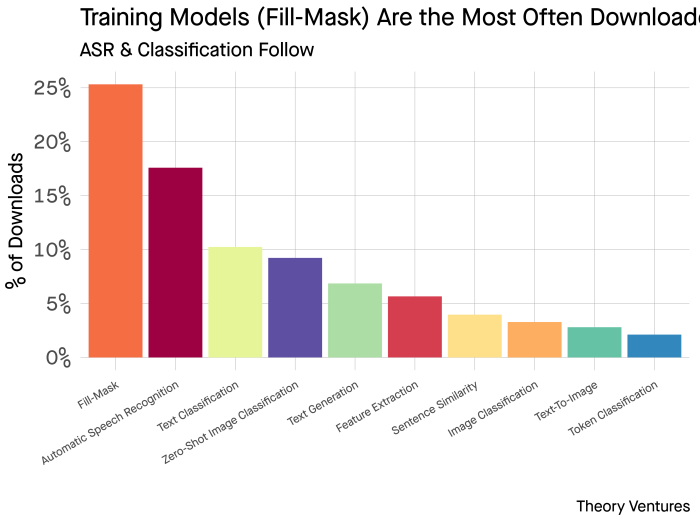
The most popular models by downloads are models for training other models, called Fill-Mask models. Then speech recognition. Third is text classification (LLMs are very good at this.) Text generation is fifth.

How about popularity? HuggingFace likes of a model are completely uncorrelated to downloads with an R^2 of 0.06.
Overall, we can conclude more lax licenses dominate the top models. Meta, Google, Microsoft, Stability, & OpenAI are important players within the open source ecosystem.
Speech is the most popular end-user application of open source models by downloads in the last month, superseded by testing – which makes sense given how many companies are building or testing LLMs.
Given all the innovation in the space, in a quarter or two, this data might be very different. Who do you think will top the charts at the end of 2024?
{kind=link}